数据仓库与数据集成数据仓库是一个集成的(Integrated),面向主题的(Subject-Oriented),随时间变化的(Time-Variant),不可修改的(Nonvolatile)数据集合,用于支持管理决策。这是数据仓库之父 Bill Inmon 在 1990 年提出的数据仓库概念。该概念里最重要的一点就是“集成的”,其余特性都是一些方法论的东西。因为数据仓库首先要解决的问题,就是数据集成,就是将多个分散的、异构的数据源整合在一起,消除数据孤岛,便于后续的分析。这个不仅适用于传统的离线数仓,也同样适用于实时数仓,或者是现在火热的数据湖。首先要解决的就是数据集成的问题。如果说业务的数据都在一个数据库中,并且这个数据库还能提供非常高效的查询分析能力,那其实也用不着数据仓库和数据湖上场了。
数据集成就是我们常称作 ETL 的过程,分别是数据接入(Extract)、数据清洗转换打宽(Transformation)、以及数据的入仓入湖(Load),分别对应三个英文单词的首字母,所以叫 ETL。ETL 的过程也是数仓搭建中最具工作量的环节。那么 Flink 是如何改善这个 ETL 的过程的呢?我们先来看看传统的数据仓库的架构。

传统的数据仓库,实时和离线数仓是比较割裂的两套链路,比如实时链路通过 Flume和 Canal 实时同步日志和数据库数据到 Kafka 中,然后在 Kafka 中做数据清理和打宽。离线链路通过 Flume 和 Sqoop 定期同步日志和数据库数据到 HDFS 和 Hive。然后在 Hive 里做数据清理和打宽。
这里我们主要关注的是数仓的前半段的构建,也就是到 ODS、DWD 层,我们把这一块看成是广义的 ETL 数据集成的范围。那么在这一块,传统的架构主要存在的问题就是这种割裂的数仓搭建这会造成很多重复工作,重复的资源消耗,并且实时、离线底层数据模型不一致,会导致数据一致性和质量难以保障。同时两个链路的数据是孤立的,数据没有实现打通和共享。
那么 Flink 能给这个架构带来什么改变呢?

基于 Flink SQL 我们现在可以方便地构建流批一体的 ETL 数据集成,与传统数仓架构的核心区别主要是这几点:
- Flink SQL 原生支持了 CDC 所以现在可以方便地同步数据库数据,不管是直连数据库,还是对接常见的 CDC工具。
- Flink SQL 在最近的版本中持续强化了维表 join 的能力,不仅可以实时关联数据库中的维表数据,现在还能关联 Hive 和 Kafka 中的维表数据,能灵活满足不同工作负载和时效性的需求。
- 基于 Flink 强大的流式 ETL 的能力,我们可以统一在实时层做数据接入和数据转换,然后将明细层的数据回流到离线数仓中。
- 现在 Flink 流式写入 Hive,已经支持了自动合并小文件的功能,解决了小文件的痛苦。
所以基于流批一体的架构,我们能获得的收益:
- 统一了基础公共数据
- 保障了流批结果的一致性
- 提升了离线数仓的时效性
- 减少了组件和链路的维护成本
接下来我们会针对这个架构中的各个部分,结合场景案例展开进行介绍,包括数据接入,数据入仓入湖,数据打宽。
数据接入
现在数据仓库典型的数据来源主要来自日志和数据库,日志接入现阶段已经非常成熟了,也有非常丰富的开源产品可供选择,包括 Flume,Filebeat,Logstash 等等都能很方便地采集日志到 Kafka 。这里我们就不作过多展开。
数据库接入会复杂很多,常见的几种 CDC 同步工具包括 Canal,Debezium,Maxwell。Flink 通过 CDC format 与这些同步工具做了很好的集成,可以直接消费这些同步工具产生的数据。同时 Flink 还推出了原生的 CDC connector,直连数据库,降低接入门槛,简化数据同步流程。

我们先来看一个使用 CDC format 的例子。现在常见的方案是通过 Debezium 或者 Canal 去实时采集 MySQL 数据库的 binlog,并将行级的变更事件同步到 Kafka 中供 Flink 分析处理。在 Flink 推出 CDC format 之前,用户要去消费这种数据会非常麻烦,用户需要了解 CDC 工具的数据格式,将 before,after 等字段都声明出来,然后用 ROW_NUMBER 做个去重,来保证实时保留最后一行的语义。但这样使用成本很高,而且也不支持 DELETE 事件。
现在 Flink 支持了 CDC format,比如这里我们在 with 参数中可以直接指定 format = ‘debezium-json’,然后 schema 部分只需要填数据库中表的 schema 即可。Flink 能自动识别 Debezium 的 INSERT/UPDATE/DELETE 事件,并转成 Flink 内部的 INSERT/UPDATE/DELETE 消息。之后用户可以在该表上直接做聚合、join 等操作,就跟操作一个 MySQL 实时物化视图一样,非常方便。

在 Flink 1.12 版本中,Flink 已经原生支持了大部分常见的 CDC format,比如 Canal json、Debezium json、Debezium avro、Maxwell 等等。同时 Flink 也开放了 CDC format 的接口,用户可以实现自己的 CDC format 插件来对接自己公司的同步工具。

除此之外,Flink 内部原生支持了 CDC 的语义,所以可以很自然地直接去读取 MySQL 的 binlog 数据并转成 Flink 内部的变更消息。所以我们推出了 MySQL CDC connector,你只需要在 with 参数中指定 connector=mysql-cdc,然后 select 这张表就能实时读取 MySQL 中的全量 +CDC 增量数据,无需部署其他组件和服务。你可以把 Flink 中定义的这张表理解成是 MySQL 的实时物化视图,所以在这张表上的聚合、join 等结果,跟实时在 MySQL 中运行出来的结果是一致的。相比于刚刚介绍的 Debezium,Canal 的架构,CDC connector 在使用上更加简单易用了,不用再去学习和维护额外组件,数据不需要经过 Kafka 落地,减少了端到端延迟。而且支持先读取全量数据,并无缝切换到 CDC 增量读取上,也就是我们说的是流批一体,流批融合的架构。

我们发现 MySQL CDC connector 非常受用户的欢迎,尤其是结合 OLAP 引擎,可以快速构建实时 OLAP 架构。实时 OLAP 架构的一个特点就是将数据库数据同步到 OLAP 中做即席查询,这样就无需离线数仓了。
以前是怎么做的呢?
之前用户一般先用 datax 做个全量同步,然后用 canal 同步实时增量到 Kafka,然后从 Kafka 同步到 OLAP,这种架构比较复杂,链路也很长。现在很多公司都在用 Flink+ClickHouse 来快速构建实时 OLAP 架构。我们只需要在 Flink 中定义一个 mysql-cdc source,一个 ClickHouse sink,然后提交一个 insert into query 就完成了从 MySQL 到 ClickHouse 的实时同步工作,非常方便。而且,ClickHouse 有一个痛点就是 join 比较慢,所以一般我们会把 MySQL 数据打成一张大的明细宽表数据,再写入 ClickHouse。这个在 Flink 中一个 join 操作就完成了。而在 Flink 提供 MySQL CDC connector 之前,要在全量+增量的实时同步过程中做 join 是非常麻烦的。

当然,这里我们也可以把 ClickHouse 替换成其他常见的 OLAP 引擎,比如阿里云的 Hologres。我们发现在阿里云上有很多的用户都采用了这套链路和架构,因为它可以省掉数据同步服务和消息中间件的成本,对于很多中小公司来说,在如今的疫情时代,控制成本是非常重要的。当然,这里也可以使用其他 OLAP 引擎,比如 TiDB。TiDB 官方也在最近发过一篇文章介绍这种 Flink+TiDB 的实时 OLAP架构。
数据入仓湖
刚刚我们介绍了基于 Flink SQL 可以非常方便地做数据接入,也就是 ETL 的 Extract 的部分。接下来,我们介绍一下 Flink SQL 在数据入仓入湖方面的能力,也就是 Load 的部分。

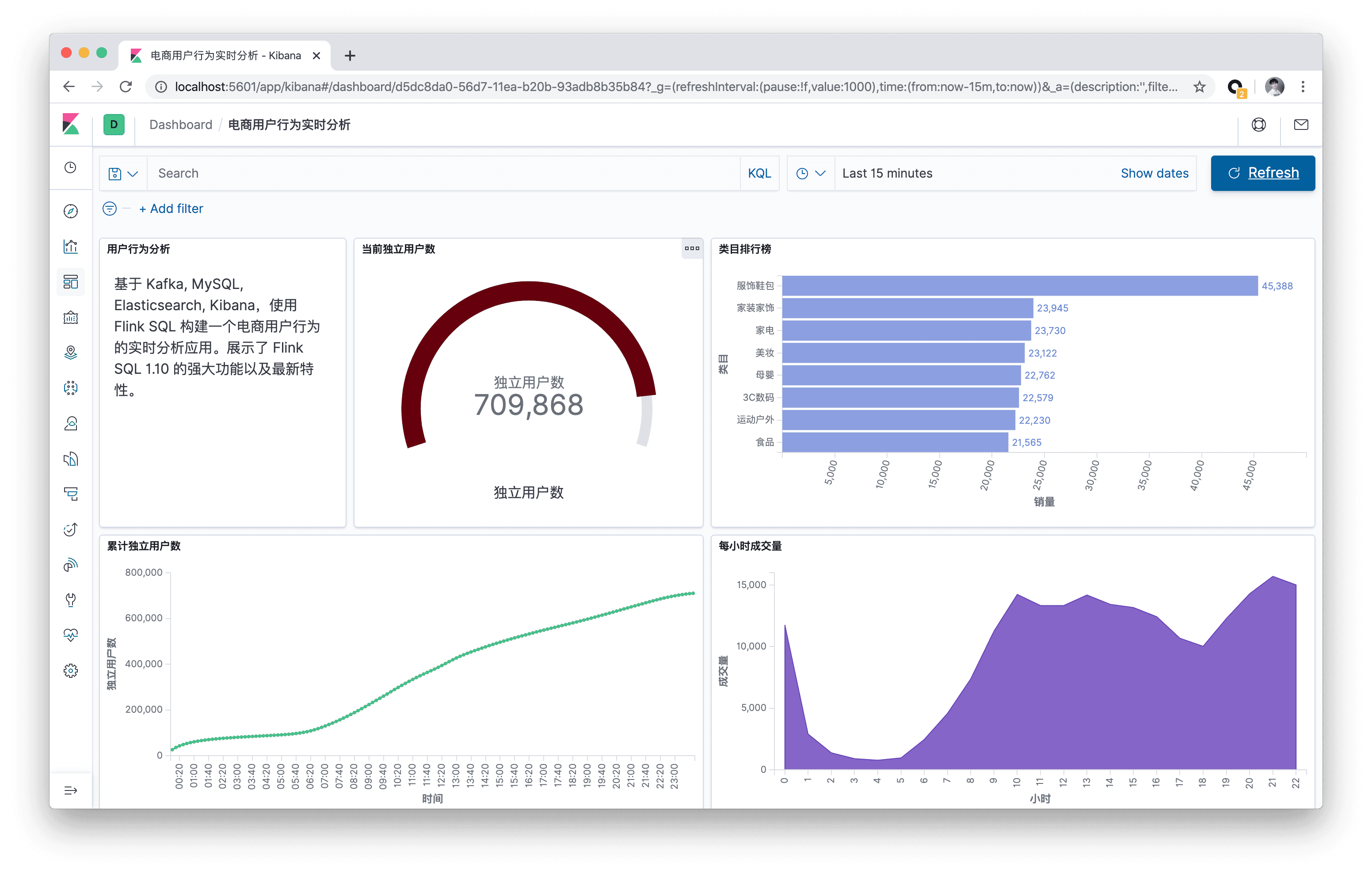
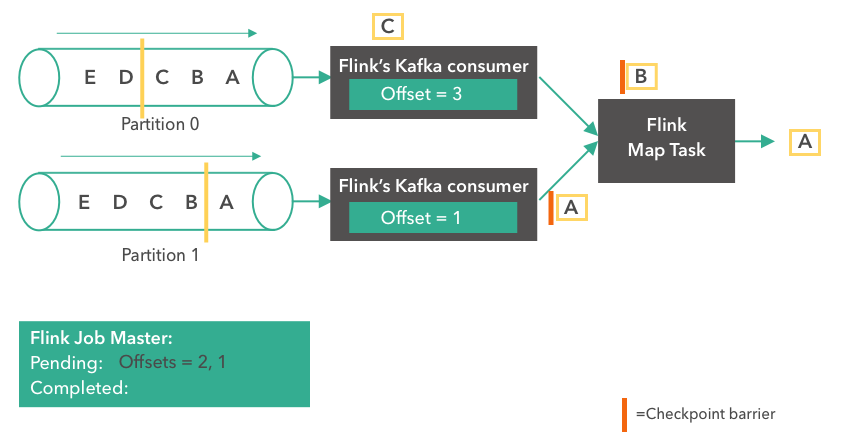
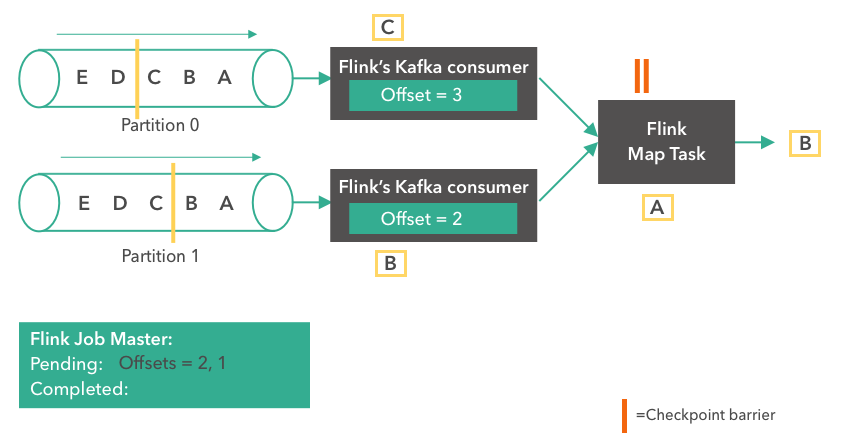
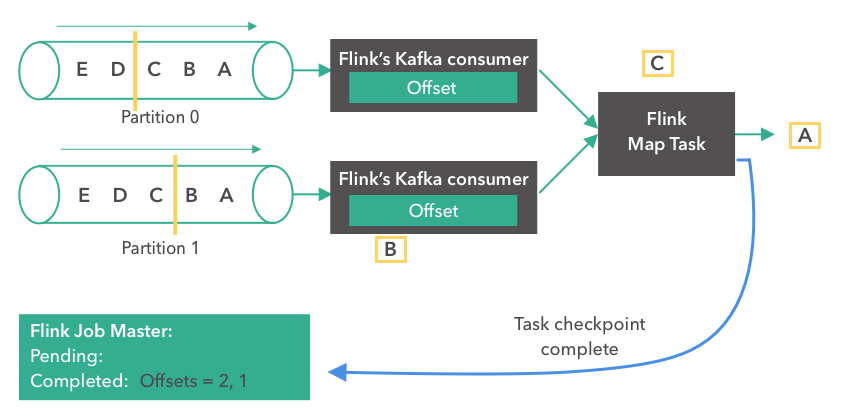
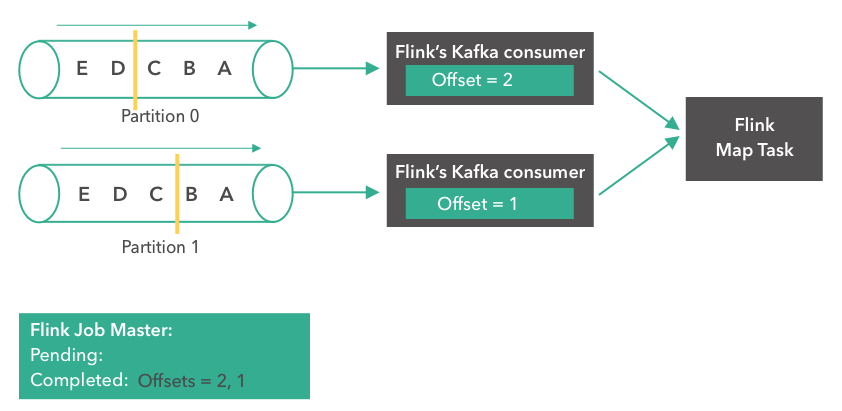
我们回顾下刚刚的流批一体的架构图,其中最核心的部分就是 Kafka 数据的流式入仓,正是这一流程打通了实时和离线数仓,统一了数仓的基础公共数据,提升了离线数仓的时效性,所以我们针对这一块展开讲一讲。

使用 Flink SQL 做流式数据入仓,非常的方便,而且 1.12 版本已经支持了小文件的自动合并,解决了小文件的痛点。可以看下右边这段代码,先在 Flink SQL 中使用 Hive dialect 创建一张 Hive 的结果表,然后通过 select from kafka 表 insert into Hive 表这样一个简单 query,就可以提交任务实时将 Kafka 数据流式写入 Hive。
如果要开启小文件合并,只需要在 Hive 表参数中加上 auto-compaction = true,那么在流式写入这张 Hive 表的时候就会自动做小文件的 compaction。小文件合并的原理,是 Flink 的 streaming sink 会起一个小拓扑,里面 temp writer 节点负责不断将收到的数据写入临时文件中,当收到 checkpoint 时,通知 compact coordinator 开始做小文件合并,compact coordinator 会将 compaction 任务分发给多个 compact operator 并发地去做小文件合并。当 compaction 完成的时候,再通知 partition committer 提交整个分区文件可见。整个过程利用了 Flink 自身的 checkpoint 机制完成 compaction 的自动化,无需起另外的 compaction 服务。这也是 Flink 流式入仓对比于其他入仓工具的一个核心优势。

除了流式入仓,Flink 现在也支持流式入湖。以 Iceberg 举例,基于 Iceberg 0.10,现在可以在 Flink SQL 里面直接 create 一个 Iceberg catalog,在 Iceberg catalog 下可以 create table 直接创建 Iceberg表。然后提交 insert into query 就可以将流式数据导入到 Iceberg 中。然后在 Flink 中可以用 batch 模式读取这张 Iceberg 表,做离线分析。不过 Iceberg 的小文件自动合并功能目前还没有发布,还在支持中。

刚刚介绍的是纯 append 数据流式入仓入湖的能力,接下来介绍 CDC 数据流式入仓入湖的能力。我们先介绍 CDC 数据入 Kafka 实时数仓。其实这个需求在实时数仓的搭建中是非常常见的,比如同步数据库 binlog 数据到 Kafka 中,又比如 join,聚合的结果是个更新流,用户想把这个更新流写到 Kafka 作为中间数据供下游消费。
这在以前做起来会非常的麻烦,在 Flink 1.12 版本中,Flink 引入了一个新的 connector ,叫做 upsert-kafka,原生地支持了 Kafka 作为一个高效的 CDC 流式存储。
为什么说是高效的,因为存储的形式是与 Kafka log compaction 机制高度集成的,Kafka 会对 compacted topic 数据做自动清理,且 Flink 读取清理后的数据,仍能保证语义的一致性。而且像 Canal, Debezium 会存储 before,op_type 等很多无用的元数据信息,upsert-kafka 只会存储数据本身的内容,节省大量的存储成本。使用上的话,只需要在 DDL 中声明 connector = upsert-kafka,并定义 PK 即可。
比如我们这里定义了 MySQL CDC 的直播间表,以及一个 upsert-kafka 的结果表,将直播间的数据库同步到 Kafka 中。那么写入 Kafka 的 INSERT 和 UPDATE 都是一个带 key 的普通数据,DELETE 是一个带 key 的 NULL 数据。Flink 读取这个 upsert-kafka 中的数据时,能自动识别出 INSERT/UPDATE/DELETE 消息,消费这张 upsert-kafka 表与消费 MySQL CDC 表的语义一致。并且当 Kafka 对 topic 数据做了 compaction 清理后,Flink 读取清理后的数据,仍能保证语义的一致性。

CDC 数据入 Hive 数仓会麻烦一些,因为 Hive 本身不支持 CDC 的语义,现在的一种常见方式是先将 CDC 数据以 changelog-json 格式流式写入到 HDFS。然后起个 batch 任务周期性地将 HDFS 上的 CDC 数据按照 op 类型分为 INSERT, UPDATE, DELETE 三张表,然后做个 batch merge。
数据打宽
前面介绍了基于 Flink SQL 的 ETL 流程的 Extract 和 Load,接下来介绍 Transformation 中最常见的数据打宽操作。

数据打宽是数据集成中最为常见的业务加工场景,数据打宽最主要的手段就是 Join,Flink SQL 提供了丰富的 Join 支持,包括 Regular Join、Interval Join、Temporal Join。

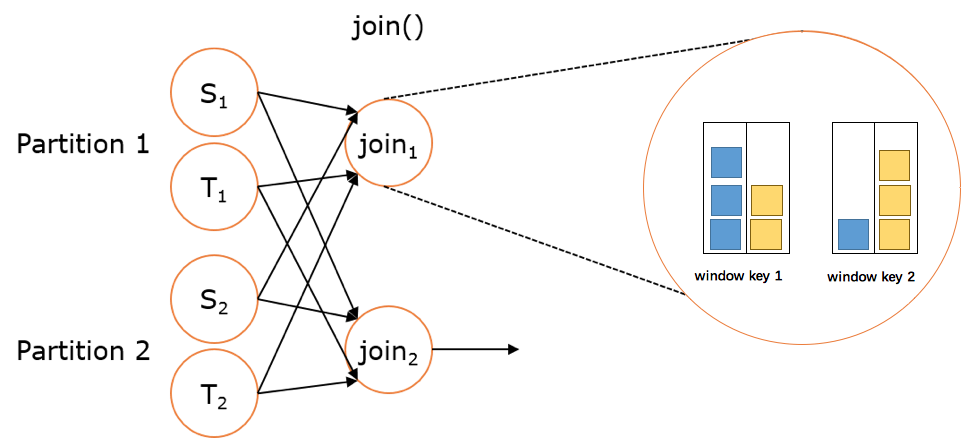
Regular Join 就是大家熟知的双流 Join,语法上就是普通的 JOIN 语法。图中案例是通过广告曝光流关联广告点击流将广告数据打宽,打宽后可以进一步计算广告费用。从图中可以看出,曝光流和点击流都会存入 join 节点的 state,join 算子通过关联曝光流和点击流的 state 实现数据打宽。Regular Join 的特点是,任意一侧流都会触发结果的更新,比如案例中的曝光流和点击流。同时 Regular Join 的语法与传统批 SQL 一致,用户学习门槛低。但需要注意的是,Regular join 通过 state 来存储双流已经到达的数据,state 默认永久保留,所以 Regular join 的一个问题是默认情况下 state 会持续增长,一般我们会结合 state TTL 使用。

Interval Join 是一条流上需要有时间区间的 join,比如刚刚的广告计费案例中,它有一个非常典型的业务特点在里面,就是点击一般发生在曝光之后的 10 分钟内。因此相对于 Regular Join,我们其实只需要关联这10分钟内的曝光数据,所以 state 不用存储全量的曝光数据,它是在 Regular Join 之上的一种优化。要转成一个 Interval Join,需要在两个流上都定义时间属性字段(如图中的 click_time 和 show_time)。并在 join 条件中定义左右流的时间区间,比如这里我们增加了一个条件:点击时间需要大于等于曝光时间,同时小于等于曝光后 10 分钟。与 Regular Join 相同, Interval Join 任意一条流都会触发结果更新,但相比 Regular Join,Interval Join 最大的优点是 state 可以自动清理,根据时间区间保留数据,state 占用大幅减少。Interval Join 适用于业务有明确的时间区间,比如曝光流关联点击流,点击流关联下单流,下单流关联成交流。

Temporal join (时态表关联) 是最常用的数据打宽方式,它常用来做我们熟知的维表 Join。在语法上,它需要一个显式的 FOR SYSTEM_TIME AS OF 语句。它与 Regular Join 以及 Interval Join 最大的区别就是,维度数据的变化不会触发结果更新,所以主流关联上的维度数据不会再改变。Flink 支持非常丰富的 Temporal join 功能,包括关联 lookup DB,关联 changelog,关联 Hive 表。在以前,大家熟知的维表 join 一般都是关联一个可以查询的数据库,因为维度数据在数据库里面,但实际上维度数据可能有多种物理形态,比如 binlog 形式,或者定期同步到 Hive 中变成了 Hive 分区表的形式。在 Flink 1.12 中,现在已经支持关联这两种新的维表形态。

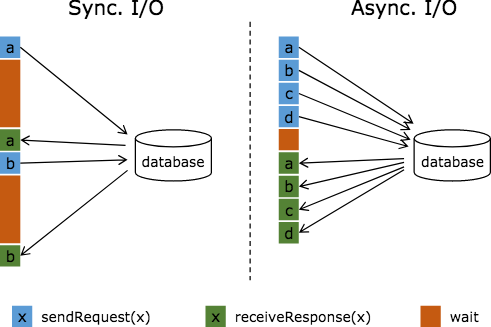
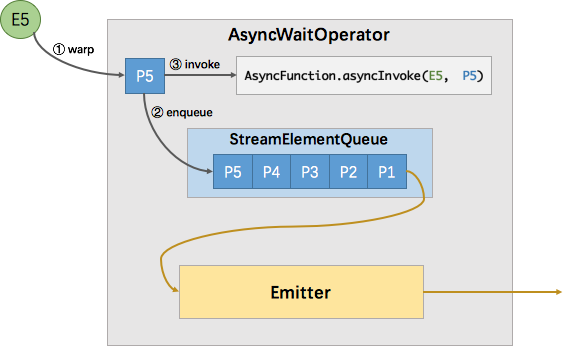
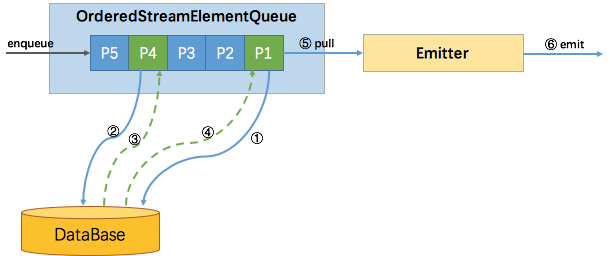
Temporal Join Lookup DB 是最常见的维表 Join 方式,比如在用户点击流关联用户画像的案例中,用户点击流在 Kafka 中,用户实时画像存放在 HBase 数据库中,每个点击事件通过查询并关联 HBase 中的用户实时画像完成数据打宽。Temporal Join Lookup DB 的特点是,维表的更新不会触发结果的更新,维度数据存放在数据库中,适用于实时性要求较高的场景,使用时我们一般会开启 Async IO 和内存 cache 提升查询效率。

在介绍 Temporal Join Changelog 前,我们再看一个 Lookup DB 的例子,这是一个直播互动数据关联直播间维度的案例。这个案例中直播互动数据(比如点赞、评论)存放在 Kafka 中,直播间实时的维度数据(比如主播、直播间标题)存放在 MySQL 中,直播互动的数据量是非常大的,为了加速访问,常用的方案是加个高速缓存,比如把直播间的维度数据通过 CDC 同步,再存入 Redis 中,再做维表关联。这种方案的问题是,直播的业务数据比较特殊,直播间的创建和直播互动数据基本是同时产生的,因此互动数据可能早早地到达了 Kafka 被 Flink 消费,但是直播间的创建消息经过了 Canal, Kafka,Redis, 这个链路比较长,数据延迟比较大,可能导致互动数据查询 Redis 时,直播间数据还未同步完成,导致关联不上直播间数据,造成下游统计分析的偏差。

针对这类场景,Flink 1.12 支持了 Temporal Join Changelog,通过从 changelog在 Flink state 中物化出维表来实现维表关联。刚刚的场景有了更简洁的解决方案,我们可以通过 Flink CDC connector 把直播间数据库表的 changelog 同步到 Kafka 中,注意我们看下右边这段 SQL,我们用了 upsert-kafka connector 来将 MySQL binlog 写入了 Kafka,也就是 Kafka 中存放了直播间变更数据的 upsert 流。然后我们将互动数据 temporal join 这个直播间 upsert 流,便实现了直播数据打宽的功能。
注意我们这里 FOR SYSTEM_TIME AS OF 不是跟一个 processing time,而是左流的 event time,它的含义是去关联这个 event time 时刻的直播间数据,同时我们在直播间 upsert 流上也定义了 watermark,所以 temporal join changelog 在执行上会做 watermark 等待和对齐,保证关联上精确版本的结果,从而解决先前方案中关联不上的问题。

我们详细解释下 temporal join changelog 的过程,左流是互动流数据,右流是直播间 changelog。直播间 changelog 会物化到右流的维表 state 中,state 相当于一个多版本的数据库镜像, 主流互动数据会暂时缓存在左流的 state 中,等到 watermark 到达对齐后再去查维表 state 中的数据。比如现在互动流和直播流的 watermark 都到了10:01分,互动流的这条 10:01 分评论数据就会去查询维表 state,并关联上 103 房间的信息。当 10:05 这条评论数据到来时,它不会马上输出,不然就会关联上空的房间信息。它会一直等待,等到左右两流的 watermark 都到 10:05 后,才会去关联维表 state 中的数据并输出。这个时候,它能关联上准确的 104 房间信息。
总结下,Temporal Join Changelog 的特点是实时性高,因为是按照 event time 做的版本关联,所以能关联上精确版本的信息,且维表会做 watermark 对齐等待,使得用户可以通过 watermark 控制迟到的维表数。Temporal Join Changelog 中的维表数据都是存放在 temporal join 节点的 state 中,读取非常高效,就像是一个本地的 Redis 一样,用户不再需要维护额外的 Redis 组件。

在数仓场景中,Hive 的使用是非常广泛的,Flink 与 Hive 的集成非常友好,现在已经支持 Temporal Join Hive 分区表和非分区表。我们举个典型的关联 Hive 分区表的案例:订单流关联店铺数据。店铺数据一般是变化比较缓慢的,所以业务方一般会按天全量同步店铺表到 Hive 分区中,每天会产生一个新分区,每个分区是当天全量的店铺数据。
为了关联这种 Hive 数据,只需我们在创建 Hive 分区表时指定右侧这两个红圈中的参数,便能实现自动关联 Hive 最新分区功能,partition.include = latestb 表示只读取 Hive 最新分区,partition-name 表示选择最新分区时按分区名的字母序排序。到 10 月 3 号的时候,Hive 中已经产生了 10 月 2 号的新分区, Flink 监控到新分区后,就会重新加载10月2号的数据到 cache 中并替换掉10月1号的数据作为最新的维表。之后的订单流数据关联上的都是 cache 10 月 2 号分区的数据。Temporal join Hive 的特点是可以自动关联 Hive 最新分区,适用于维表缓慢更新,高吞吐的业务场景。

总结一下我们刚刚介绍的几种在数据打宽中使用的 join:
- Regular Join 的实效性非常高,吞吐一般,因为 state 会保留所有到达的数据,适用于双流关联场景;
- Interval Jon 的时效性非常好,吞吐较好,因为 state 只保留时间区间内的数据,适用于有业务时间区间的双流关联场景;
- Temporal Join Lookup DB 的时效性比较好,吞吐较差,因为每条数据都需要查询外部系统,会有 IO 开销,适用于维表在数据库中的场景;
- Temporal Join Changelog 的时效性很好,吞吐也比较好,因为它没有 IO 开销,适用于需要维表等待,或者关联准确版本的场景;
- Temporal Join Hive 的时效性一般,但吞吐非常好,因为维表的数据存放在cache 中,适用于维表缓慢更新的场景,高吞吐的场景。
总结

最后我们来总结下 Flink 在 ETL 数据集成上的能力。这是目前 Flink 数据集成的能力矩阵,我们将现有的外部存储系统分为了关系型数据库、KV 数据库、消息队列、数据湖、数据仓库 5 种类型,可以从图中看出 Flink 有非常丰富的生态,并且对每种存储引擎都有非常强大的集成能力。
横向上我们定义了 6 种能力,分别是:
- 3 种数据接入能力:全量读取、流式读取、CDC 流式读取。
- 1 种数据打宽能力:维度关联。
- 2 种入仓/入湖能力:流式写入、CDC 写入。
可以看到 Flink 对各个系统的数据接入能力、维度打宽能力、入仓/入湖能力都已经非常完善了。在 CDC 流式读取上,Flink 已经支持了主流的数据库和 Kafka 消息队列。在数据湖方向,Flink 对 Iceberg 的流式读取和 CDC 写入的功能也即将在接下来的 Iceberg 版本中发布。从这个能力矩阵可以看出,Flink 的数据集成能力是非常全面的。
在未来的版本中,我们也将持续优化 Flink 数据集成的能力,扩展上下游生态。也非常欢迎大家使用和反馈。
]]>